
The CDC 6600

Synonymous with the origin of supercomputing is Seymour Cray (pictured at the left). For at least two decades, starting at Control Data Corporation in 1964, then at Cray Research, Cray's computers were the fastest scientific computers in the world. They are still what many people think of when they imagine a supercomputer.
In the late 1950s, Seymour Cray followed a number of other Engineering Research Associate (ERA) employees to the newly formed Control Data Corporation (CDC) where he continued designing computers. However, he was not interested in CDC’s main business of producing upper-end commercial computers. What he wanted to do was to build the fastest scientific computer in the world.
President Bill Norris did not want to lose him, so he funded him to begin working on the CDC 6600, which was to become the first commercially successful supercomputer. See the 6600 photo at the left immediately below. In addition to Seymour Cray on the 6600 was Jim Thornton, who was responsible for the "detailed design" and also a hidden genius behind the 6600.
Cray was quoted as saying, “Anyone can build a fast CPU (central processing unit). The trick is to build a fast system.” The 6600 team designed a total system that was very efficient which meant, among other things, designing faster IO (input-output) bandwidth. (Otherwise, the ultrafast processor would spend time idling while waiting for data to come from memory.) They also made sure that signal arrivals were properly synchronized. In addition, they focussed on an advanced cooling system as removing heat is a major issue in a very high speed computer system.

The 6600 Central Processing Unit. Seymour Cray made several big architectural improvements in the 6600 central processor unit. The first was significant parallelism at the instruction level. Within the "CPU itself", there were multiple sections which operated in parallel allowing it to begin the next instruction while still computing the current one, as long as the current one was not required by the next one.
A scoreboard was used to dynamically schedule the instruction pipeline so that the instructions could execute out of order when there were no conflicts and the hardware was available. In a scoreboard, the data dependencies of every instruction are logged. Instructions are released only when the scoreboard determines that there are no conflicts with previously issued incomplete instructions.
The system had a 10 megahertz (MHz) clock speed (the basic computer speed was 10 million clock cycles per second), but used a four-phase signal, so the system could at times operate at 40 MHz.
The 6600 also had an 8 word "instruction cache" which retained frequent instructions to reduce the time the CPU spent waiting for the next instruction to come from memory. Each CPU "word" was 60 bits in length, i.e. ten 6 bit characters (ASCII standards had not yet been created). Instructions were either 15 bits or 30 bits, so the instruction cache could hold between 16 and 32 instructions. At this point in his career, Cray did not believe that a parity bit was necessary, so each character or number was only 6 bits in length.
A second big architectural improvement was that the central processor unit also contained 10 parallel processors (PPs) so it could operate on ten different types of instructions simultaneously. The CPU read and decoded instructions from memory and then passed them onto the PP units for further processing including IO operations. See the right hand side of the chart below.
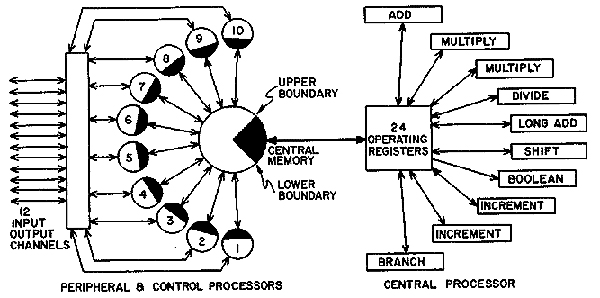
The 10 independent parallel processors (PPs) were made up of the following types: an add unit, 2 floating point multipliers, a floating point divider, a long add unit for 60 bit words, a shift unit, a Boolean algebra unit, 2 incrementers that performed memory loads and stores, and a branch unit.
Although there were 10 parallel processors, the CPU could only handle a single unit at a time. The CPU did not do any IO which is a very slow process relative to the CPU clock. This split CPU approach was very unique at the time.

Another improvement was the size of the instruction set. At the time, it was normal to have a large multi-tasking CPU manipulating a large complicated instruction set. This meant that the clock speed tended to run relatively slow. Cray instead used a small CPU with a small instruction set, handling only arithmetic and logic operations, which meant it could have a much faster clock speed. This architecture was really the forerunner of the “reduced instruction set computer” (RISC) designs which gave rise to the currently very popular ARM processors that surfaced in the early 1980s.
The peripheral processors were housed in a ‘barrel’, and would be presented to the CPU sequentially. On each "barrel rotation" the CPU would operate on the instruction in the current processor, then the next processor and so on back to the first one.
This meant that multiple instructions could be processing in parallel and the peripheral processors could handle I/O and other operations while the CPU ran its arithmetic and logic operations independently. Also consider that the peripheral processor IO speed to a tape or disk drive was much, much slower than one to main memory.
The computer console had two cathode ray tube (CRT) screens. See the picture above. The CRT display console was a significant departure from conventional (IBM) computer consoles at the time. Those contained hundreds of blinking lights and switches for every state bit in the machine. By comparison, the 6600 console was an elegant design: simple, fast and reliable.

The character set contained 64 characters, which included all upper case letters, digits, and a few punctuation marks. There were enough characters to write a FORTRAN program which was the main language of scientists and other high speed users at the time. 64 characters were also enough to allow normal scientific or financial reports to be printed.
For the IO tasks normally dealt with by other CPU main processors, Cray instead used the secondary peripheral processors. The peripheral processors used 12-bit words. Nearly all of the operating system, and all of the I/O ran on the peripheral processors to free up the CPU for main user programs. Each peripheral processor had its own memory of 4096 12-bit words. This memory served for both I/O buffering and operating system storage.
The 6600 had 400,000 transistors and more than 100 miles of wiring. It's 10 MHz clock cycle was about ten times faster than other computers on the market at that time. It executed a dizzying 3,000,000 instructions per second (3 megaflops). In addition to the clock being super fast, the simple CPU instruction set took fewer clock cycles to execute an instruction.
Three doors of logic swung out from each of the four bays of the “plus sign" (i.e. + sign) main housing unit. See the photo to the left with 3 doors open. A refrigeration compressor was located in the end of each bay behind a closed door. The goal was to minimize the length of the interconnection wiring by concentrating all of it at the central intersection of the four bays of twelve doors. With all these unique design improvements, the speed-up in data processing was phenomenal!
In 1970 Vice President Jim Thornton, the 6600 detail design manager, released a very good 196 page book thoroughly explaining the 6600 design (including a Forward by Seymour Cray himself). To download a free licensed (see page 196) PDF copy over the internet click here.

The 6600 Memory System. The CPU had a directly addressable local memory of 128K words housed in the mainframe. (Converted to modern terms with 8-bit bytes, the central memory was about one megabyte). Individual user programs were restricted to use only a contiguous area of central memory and were limited to 128K words. The memory bandwidth was one 60 bit word every 100 nanoseconds or a 100 million 6 bit characters per second (same speed as the CPU).
Excluding the first seven CDC 6600 machines, from then on an optional Extended Core Storage (ECS) memory could be added to the basic system. The ECS could contain up to 2 million words in four 512k unit increments. The ECS overcame the rather small size (128k words) of the main memory unit. The ECS was built from a different type of core memory than was used in the central memory. See a photo of a core ECS memory module to the left. This made it economical for the ECS to be significantly larger than the main memory. The primary reason for the economical benefit was that ECS memory was wired with only two wires per core in contrast with five for the central memory. However, because it performed word wide transfers of 60 bits, the ECS transfer rate was the same as that of the main memory.
By using a coupler-controller attached to the main memory, the CPU could directly perform block memory transfers between a user's program (or operating system) and the ECS unit. Also, a second CPU could be attached to the ECS and share the large memory unit. As wide data paths were used, sending and receiving information to and from the ECS was a very fast operation.

A Brief 6600 History. With its introduction in September of 1964, the 6600 was three times faster than the previous record holder, the IBM 7030 Stretch. This upset IBM CEO Tom Watson very much, who then wrote to his management: "I understand that in the laboratory developing the 6600 system there are only 34 people including the janitor. I fail to understand why we have lost our industry leadership position by letting someone else offer the world's most powerful computer." This memo became known as "The Janitor Memo," and it showed the impact Control Data had on the leadership of IBM.
The first 6600 system went to CERN to analyze bubble chamber tracks and it stunned the computer community. The 6600 remained the fastest computer between its introduction in 1964 until the introduction of the CDC 7600 in 1969 (also designed by Seymour Cray).
Control Data broadened the 6600 product line to include the 6400, 6500, and 6700 systems, of which some were cheaper and some more expensive than the original 6600. Control Data sold over one-hundred 6000 type machines for a price of $6M to $10M (million) each. Many of these went to various nuclear bomb related labs, and quite a few found their way into university computing labs. The 6600 was indeed the first supercomputer. Top
The CDC 7600

Soon after the initial 6600s were delivered, Seymour Cray turned his attention to its replacement - the CDC 7600. This time setting a 7600 goal of 10 times the performance of the 6600. The 7600 ran at 36.4 MHz (27.5 nanosecond clock cycle) and had a 65K word primary memory using magnetic core and a variable-size (up to 512K word) secondary memory. It was generally about ten times as fast as the CDC 6600 and could deliver about 10 megaflops on hand-compiled code, and had a peak performance of 36 megaflops.
The 7600 was an architectural landmark, and most of its features are still standard parts of current computer designs. In order to make the speed of the 7600 instruction execution faster than the 6600, Cray introduced the concept of an "instruction pipeline". Each 6600 functional unit consisted of several sections that operated in turn. For example, an addition unit might have circuitry dedicated to retrieving the operands from memory, then the math unit would process it, and finally another unit to send the results back to memory. At any given instance only one part of the unit was active while the rest waited their turn.
A "pipeline" improves on the above by feeding in the next instruction before the first has completed using up that idle time. For instance, while one instruction is being added together, the next add instruction can be fed in so the operand fetch circuits can begin their work. That way as soon as the current instruction completes and moves to the output circuitry, the next addition is ready to be fed in. In this way each functional unit works in "parallel", as well as the machine as a whole. The improvement in performance generally depends on the number of steps the unit takes to complete. For example, the 6600's multiply unit took 10 cycles to complete, so by pipelining the units the 7600 could be expected to produce about 10 times the speed.
The 7600 had two main core memories. Small core memory held the instructions currently being executed and the data currently being processed. It had an access time of ten of the 27.5 nanosecond (ns) minor cycle times and a 60-bit word length. The large core memory held data ready to transfer to the small core memory. It had an access time of 60 of the 27.5 ns minor-cycle times and a word length of 480 bits. Accesses were fully pipelined and buffered, so the two memories had the same sequential transfer rate. The two memory units worked in parallel, so the sequential transfer rate from one to the other was also 60 bits per each 27.5 ns minor-cycle time.
For the period from 1969 to 1975, the CDC 7600 was generally regarded as the fastest computer in the world. In benchmark tests in early 1970, the 7600 was found to be faster than its IBM rival, the System/360 Model 195. The 7600 system sold for about $5M in its base configuration and considerably more as options were added. Due to a 1969 slowdown in the US economy, some reliability issues due to the machines complexity, and a new operating system, only a few dozen machines were sold to very high end customers around the world. Top
The Cray-1

Cray Research. About 1970 after the CDC 7600 was in production, Seymour Cray began working on a follow up product - the 8600. The system was extremely complex and by 1972 he realized that it could not be commercialized. He decided that he needed to scrap the design and start over. 1972 was not a good year for Control Data and President Bill Norris informed Cray that CDC could not afford the resources to start again fresh on a new design.
Cray then decided to go out on his own and formed a company called Cray Research with research facilities in Chippewa Falls, Wisconsin. Many former CDC employees joined him and spent the next four years working on the Cray-1. Cray was well known in financial circles and had no trouble raising millions of dollars from venture capitalists and other investors. The parting between Bill Norris and Seymour Cray was cordial with Bill Norris investing $300,000 of his personal money into the new venture.
Vector Processing. Instead of pipelining just the instructions, vector processing also "pipelines the data itself". The processor is fed instructions that say not just to add A to B, but to add all of the numbers from "here to here" to all of the numbers from "there to there". Instead of constantly having to decode instructions and then fetch the data needed to complete them, the processor reads a single instruction from memory, and it simply "implies in the definition of the instruction itself" that the instruction will operate again and again on another item of data at an address one increment larger than the last one. This allowed for significant savings in decoding and execution times.
There are several savings inherent in a vector processing approach. First, only two address translations are needed. Depending on the architecture, this can represent a significant savings all by itself. Another saving is fetching and decoding the instruction itself, which has to be done only one time instead of x times.
The code itself is also smaller, which can lead to more efficient memory use. But more than that, a vector processor may have multiple functional units processing numbers in parallel. This simplifies the control logic required, and can improve performance by avoiding stalls.

Cray-1 Innovations. The Cray vector processing implementation allowed several different types of operations to be carried out at the same time. Consider code that adds two numbers and then multiplies by a third. In the Cray, these would all be fetched at once, and both added and multiplied in a single operation. He decided that in addition to fast vector processing, his design would incorporate excellent all-around scalar performance. That way when the machine switched modes from vector back to scalar, it would still provide superior performance.
Additionally, they noticed that the workloads could be dramatically improved in most cases through the use of registers. Since the typical vector operation would involve loading a small set of data into the vector registers and then running several operations on it, the vector system of the Cray-1 design had its own separate pipeline.
For instance, the multiplication and addition units were implemented as separate hardware, so the results of one could be internally pipelined into the next, the instruction decode having already been handled in the machine's main pipeline. Cray referred to this concept as "chaining", as it allowed programmers to "chain together" several instructions and extract higher performance.

The Cray-1 was the first Seymour design to use integrated circuits (ICs). Although ICs had been available since the 1960s, it was only in the early 1970s that they reached the performance level necessary for high-speed applications.
The Cray-1 only used four different IC types. These integrated circuits were supplied by Fairchild Semiconductor and Motorola. In all, the Cray-1 contained about 200,000 IC gates. Integrated circuits were significantly faster and smaller than discrete components.
The high-performance circuitry generated considerable heat, and Cray's designers spent as much effort on the design of the refrigeration system as they did on the rest of the mechanical design. The cooling system was the first ever freon based system.
Serial number one Cray-1 was delayed six months due to problems in the cooling system. Lubricant that was normally mixed with freon to keep the compressor running would leak through the seals and eventually coat the printed circuit boards with oil until they shorted out. New welding techniques had to be used to properly seal the tubing. The only patents issued for the Cray-1 computer were associated with the cooling system design.

In order to obtain maximum speed, the entire chassis was bent into a large C-shape. Speed dependent portions of the system were placed on the "inside edge" of the chassis, where the wire lengths were shorter. This allowed the cycle time to be decreased to 12.5 nanoseconds (80 MHz), fast enough to easily beat the CDC 7600. The Cray-1 was the first commercially successful vector processing computer.
The CPU was built as a 64-bit system compatible with ASCII standards, a departure from the CDC 6600 and 7600, which were 60-bit machines. Addressing was 24-bit, with a maximum of 1,048,571 64-bit words (8 megabytes) of main memory. Each word also had 8 parity bits for a total of 72 bits (parity on the Cray-1 was a first for Seymour).
Memory was spread across 16 interleaved memory banks, each with a 50 ns cycle time, allowing four 64 bit words to be read each cycle. The overall performance of the Cray-1 was generally advertised as 160 megaflops per second.
Cray Research complemented its supercomputers with good software programs, releasing the Cray Operating System (COS) and Cray Fortran Compiler (CF77) in 1977.
A Brief Cray-1 History. The Cray-1 was announced in 1975 and serial number 1 (sn #1) was delivered to Los Alamos National Laboratory for a 6 month beta trial in 1976. The chart to the left was made by Los Alamos Labs. The first production Cray-1 (sn #3) was delivered to the National Center for Atmospheric Research (NCAR) in 1977. NCAR calculated that the throughput of the system was 4.5 times the CDC 7600.
During its early years of operation, Cray Research sold its supercomputers to government laboratories and agencies. The main application of supercomputers was in simulations, wherein computer models were used to analyze the response pattern likely to take place in a system composed of physical variables. In 1978 however, Cray Research obtained its first order from a commercial organization. Cray Research initially expected to sell about a dozen machines and set the selling price accordingly. However, ultimately over 80 Cray-1s of all types were sold, priced from $5M to $8M. The worldwide successful Cray-1 made Seymour Cray a celebrity and Cray Research became a very successful company. Top
The Cray Research X-MP

About 1979 Seymour Cray began working on the Cray-2. While he worked on the Cray-2, another Cray Research team headed by Steve Chen, in 1982 delivered a two-processor shared memory system, with an upgraded Cray-1 architecture all in a one cabinet system. It was called the X-MP and looked just like the Cray-1. See the X-MP photo to the left. The CRAY X-MP was three times as fast as the CRAY-1.
The X-MP was another big Cray Research success. It was the world's fastest computer system from 1983 to 1985. The X-MP CPU ran at 105 MHz with a 9.5 nanosecond clock cycle time.
In 1984, improved models of the X-MP were announced, consisting of one, two, and four-processors with 4 and 8 million word memory configurations. The four-processor X-MP delivered 1.9 gigaflops of peak performance - the fist supercomputer with over a gigaflop of peak performance.
In 1987 Cray Research delivered its 200th computer system. This was especially noteworthy since it had taken from 1976 to 1985 to reach a 100 computer installations. Top
The Cray-2

Not happy with constant management interruptions at the now successful and much larger Cray Research company, in 1980 Seymour Cray resigned the Cray Research CEO position to become an independent contractor. He remained located in Chippewa Falls. However, Cray retained his close ties with the company as a member of the Cray Research Board of Directors.
The Cray-2 contained four processors each with its own vector processor built using "emitter-coupled logic" and manufactured by Cray Research. See the Cray-2 photo to the left.
The Cray-2 main memory was a dramatic innovation. The first Cray-2 delivered to a customer had more physical memory than all previously delivered Cray machines combined. The main memory size was 256 million 64 bit words (2 gigabytes). Seymour also increased the number of channels from the main memory to the four processors. The Cray-2 memory was so large that entire data sets could be read into it. However, the processors ran so much faster than the main memory that initially they spent a long time just waiting for data to arrive.
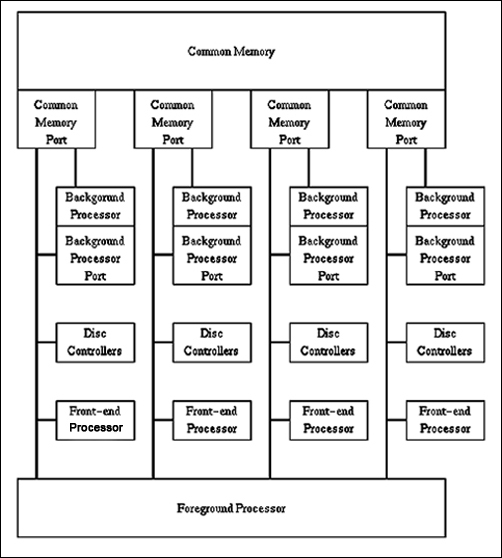
To avoid the wait problem, the "background processors" were each configured with a relatively small 16,384 word (131 kilobyte) block of the very fastest memory possible, called the “local memory”. The local memory was not a cache, but a super fast memory as part of each of the four background processors with very high speed channels to the main common memory. See the Cray-2 architecture diagram to the left.
The local memory was fed data by a “foreground processor” which was also attached to the main memory through high speed channels. Introduced quite late in the development cycle, Seymour called the large memory/local memory arrangement a "Mid-course Correction".
It was the foreground processor's task to "run" each computer, handle storage and efficiently use the multiple channels into and out of the main memory. The operating system ran in the foreground processor which acted as the total system manager and also the input/output manager.
The foreground processor drove the background processors by passing to them the instructions they would run. The background processors then completed the computational tasks.
The foreground processor had its own instruction and data memory, a 32-bit integer arithmetic unit and a real-time clock. (Modern computers use a similar design, but the foreground processor is now called the load/store unit.)
The main memory banks were arranged in quads so they could all be accessed at the same time. This allowed programmers to position data streams across memory banks to achieve higher parallelism.

Emitter-coupled logic (ECL) is a high-speed integrated circuit logic family wherein the current is approximately constant with very little noise. ECL was invented by IBM in 1956 and was used wherever very high speed performance was needed.
The negative aspect of ECL was that it consumed a lot of power. It was eventually replaced by much cooler CMOS circuitry that could be air-cooled instead of being refrigerator-cooled. See the eight layer Cray-2 computer module to the left. The Cray-2 ran at 250 MHz with a very deep pipeline. The deep pipeline was harder to code than the shorter pipe Cray-1 or X-MP.
The Cray-2 cooling system was another innovation. The ECL logic cards were packed so densely that there was no way a conventional air-cooled system could work. There was too little room for air to flow between the integrated circuits. Instead the system had to be immersed in a tank of a new inert liquid from 3M called Fluorinert.

The cooling liquid was forced sideways through the modules under pressure. The flow rate was roughly one inch per second. The heated liquid was then cooled using a chilled water heat exchanger positioned several feet behind the main frame. See the cooling tower photo to the left.
The Cray-2 system was 12 times faster than the Cray-1 and was about twice as fast as the X-MP. The trade-off of introducing a very large (but somewhat slower) main memory allowed much larger 3D (as opposed to 2D) simulations to be run on the Cray-2, a big selling point. The whole data set could now be positioned in main memory as opposed to being located on hard drives. However, the local memory/main memory concept was difficult to properly program. This was one of the limiting factors in the number of Cray-2 units sold.
The first Cray-2 was delivered in 1985, six years after its start. Purchasing the machine made sense only for those users with huge scientific data sets to process. Due to its very expensive large main memory and some programming issues, the market for the Cray-2 turned out to be limited. Cray Research sold 27 Cray-2 type systems for an average price of about $14 million which resulted in about $380 million of product revenue (not counting maintenance revenue).
In 1986 one year after the first Cray-2 delivery, Cray Research introduced a new software operating system - UNICOS. It combined the AT&T UNIX System V with the COS operating system (hence UNI COS). This software advance was especially important because UNIX was the industry standard for most scientific applications. Top
The Cray-3

Seymour started working on the Cray-3 in 1988, with a goal of a first delivery in 1991. Cray generally set himself a goal of producing new machines that were 10 times the performance of the previous model, but in the case of the Cray-3, the goal was set at 12 times. Cray had always attacked the problem of increased speed with three simultaneous advances: more functional units to give the system higher parallelism, tighter packaging to decrease signal delays, and faster components to allow for a higher clock speed. Of the three, Cray was normally least aggressive on the last item. His designs tended to use only components that were already in widespread use, as opposed to leading-edge components.
When the Cray-3 was begun in 1988, it was a time when the supercomputer market was shrinking from a 50% annual growth rate in 1980 to about 10% in 1988. The changing political climate (collapse of the Russian empire and the end of the Cold War) resulted in fewer supercomputers being sold to the military. Because the CRAY-3 project contained a major element of risk due to its innovative technology, CEO John Rollwagen initiated a second project based on a further upgrade of the basic X-MP technology.
During 1989 Cray Research was in the process of developing both the Cray-3 and the C90, two machines of roughly similar power. The Cray-3 was designed to be compatible with the Cray-2, while the C90 was compatible with the X-MP series. With only 27 Cray-2s having been sold, management decided that the Cray-3 should be put on "low priority" development. This was not the first time this had happened to Seymour and as in the past, he decided to form another company to continue full development of the Cray-3. The new company, Cray Computer Corporation (CCC), was based in Colorado Springs, Colorado. Cray Research retained a minority equity stake in CCC as CCC continued to work under contract to Cray Research.

Cray had intended to use gallium arsenide circuitry in the Cray-2, which would not only offer much higher switching speeds, but also used less energy and thus run cooler as well. At the time the Cray-2 was being designed, the state of GaAs manufacturing simply wasn't up to the task of supplying a supercomputer. By the mid-1980s, things had changed and Cray decided it was the only way forward. Given a lack of investment on the part of large chip makers, Cray decided the only solution was to invest in a GaAs chip making startup, GigaBit Logic, and use them as an internal supplier. See a typical Cray-3 computer module to the left.
By 1991, development was again behind schedule. Development slowed even more when Lawrence Livermore National Laboratory cancelled its order for the first machine in favor of the C90. The first (and only) Cray-3 system was eventually delivered to the National Center for Atmospheric Research (NCAR) in May of 1993. NCAR's model was configured with 4 processors and one gigabyte of common memory. The machine was essentially still a prototype and CCC used the installation as a beta site to finalize the design.
By this time a number of massively parallel machines were coming into the market at price performance ratios the Cray-3 could not touch. By March of 1995 NCAR had not yet paid for the machine when CCC ran out of money and filed for Chapter 11 bankruptcy. CCC had burned through about $300 million of financing. No more Cray-3s were ever built. Top
The Cray-4

The remains of CCC became Cray's final corporation, SRC Computers Inc. (SRC were Seymour's initials.) Seymour Cray had always resisted the massively parallel solution to high-speed computing, offering a variety of reasons that it would never work as well as a few very fast processors. However, by the mid-1990s modern "compiler" technology made developing programs for massively parallel machines not much more difficult than simpler computers. Cray finally saw the light and started the design of his own massively parallel machine - the Cray-4.
See the the only known Cray-4 processor module at the left - a 4 inch by 5 inch module with 90 electrical layers, each 0.33 inches thick.
The new design concentrated on communications and memory performance, the bottleneck that held back many parallel designs. Full design had just started when Cray suddenly died as a result of a car accident. SRC Computers carried on the development and today specializes in reconfigurable computing. (High-Performance Reconfigurable Computing (HPRC) is a computer architecture that combines field programmable gate arrays (FPGAs) with multi-core processors.)
The Tragic Ending. Seymour Cray died on October 5, 1996 at the age of 71 of head and neck injuries suffered on September 22, 1996 in a traffic collision. Another driver tried to pass Cray on Interstate 25 in Colorado Springs. But the driver struck a third car that then struck Cray's Jeep Cherokee, causing it to roll three times. Cray underwent emergency surgery and remained in the hospital until his death two weeks later. Top
Jim E. Thornton

After being the lead detail design manager on the CDC 6600 and 7600 with Seymour Cray in the early 1970s, Jim Thornton led a different CDC team to produce a vector processing supercomputer called the STAR 100. The machine was aimed at vector processing workloads where it performed very well. However, on non-vector scalar programs or scalar parts of complex programs, it did poorly as it was designed strictly for vector processing. On most scientific workloads it performed about the same as the 7600. Only 2 STAR 100 systems were sold, one to the Lawrence Livermore National Laboratory and one to NASA Langley Research Center.
Jim Thornton left CDC in 1974 along with Peter Jones to form Network Systems Corporation, a high speed networking company that interfaced various supercomputers and also the emerging internet. Network Systems did very well in the late 1970s and early 1980s. In the late 1980s, local area networks sprang up using low cost, work station networks. Also, Cisco came on the scene with medium priced mainframe networking offerings.
Network Systems had a hard time keeping up with the falling prices and was eventually purchased by Storage Technology in 1995. Storage Technology was purchased by Sun Microsystems in 2005 and Sun Microsystems was purchased by Oracle Corporation in 2009. In the meantime, Jim Thornton died of cardiovascular failure in January, 2005. He was 79 years old.
(The author, a former Group VP of CDC who started in June, 1964, knew Seymour Cray from senior CDC meetings and was a very good friend of Jim Thornton.)